Data Collection
Data Collection is a scheduling system that allows the user to schedule job runs. It can be turned on and off in the Data Collection index page.
Data collection schedules can be run for a job group or individual job. For the purposes of data collection jobs it is suggested you use the Reporting Connector and do not have Include Binaries checked in the Details tab. Simflofy can create the necessary auditing data without the actual file content.
How to use Data Collection
The Set Info Pane will show you basic information about the various collections in the data set, as well as allowing you to delete individual runs.
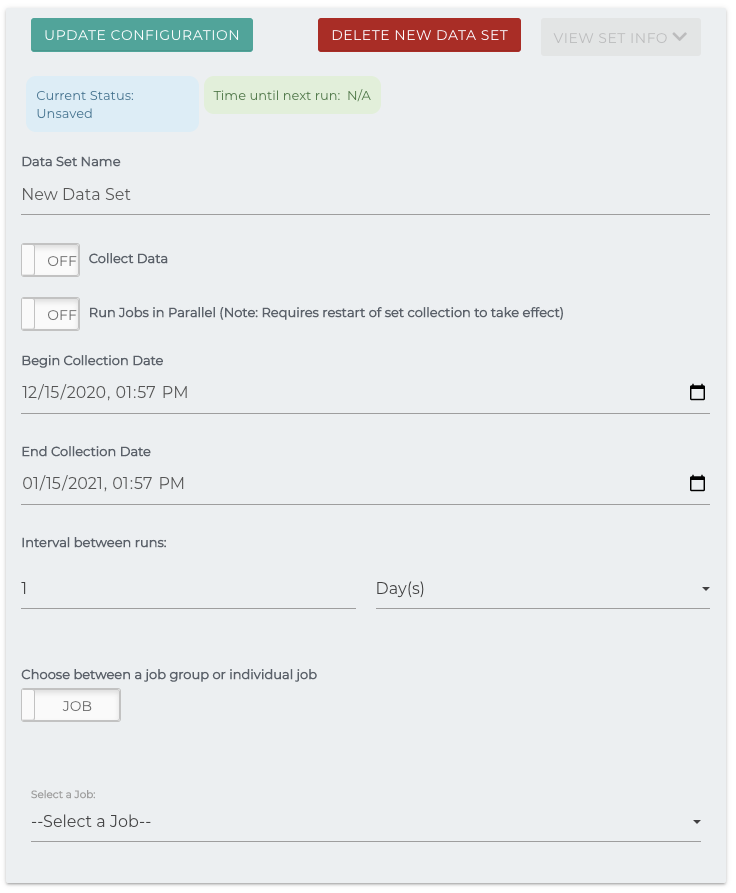
The data collection service runs in the background based on properties set either in simflofy-global.properties or in the Admin Properties page. It checks each data set (created once you hit Set Collection Schedule) to see if that job group needs to be run based on whether Collect Data is 'on'.
Collection Statuses: Sets can have one of three statuses
- OFF - The service will not collect data for this group
- WAITING - The job group is between collections
- COLLECTING - The jobs in the job group are currently running
Time until next run: As it reads. If this runs to zero, it will not refresh unless the schedule is closed and reopened. Will Display as NA if performing a run.
Collect Date: If true, the collection will run based on the collection dates.
Run jobs in parallel: Run all jobs in the set simultaneously. The default is to run them in prescribed order set on the job group.
Collection dates: Dates over which data will be collected.
- If the "From" time is set to a value before the current date/time, the run will begin immediately.
- The "To" time and Interval are checked upon completion of a collection run to determine whether the set should run again.
Interval: The interval between collections will dictate how often the jobs are going to run.
- It is suggested you determine the general length of the jobs you wish to run to avoid overlap. The Set Info pane provides an average run time for the data set.
- Setting the collection interval to Once will turn off collection after a single run.
- Interval below 3 minutes are not allowed, as they cause unpredictable behavior.
Choose between a job group or individual job
- If selecting a job group, you can choose the run order by dragging. The top job is run first.
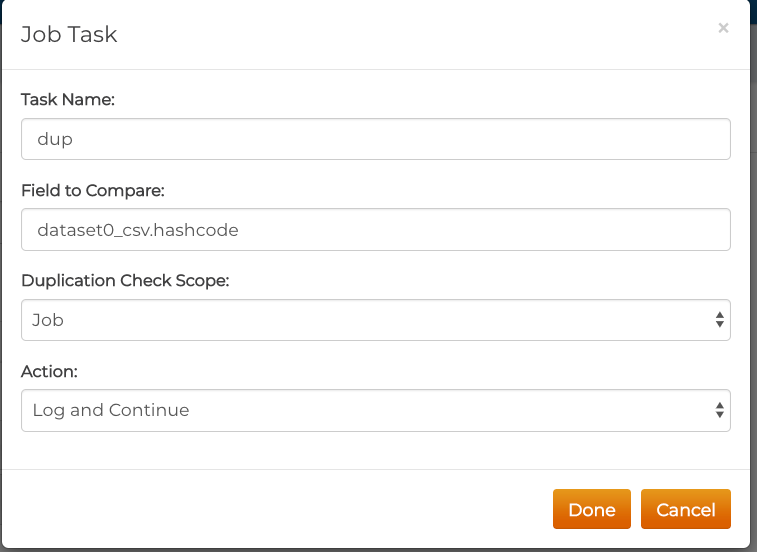
Example Duplicate Checking
If you wish to collect information on duplicate data, use the Duplication
Check Task. As of the inclusion of Data Collection, you do not need to include
a binary for duplication checks. If you declare a field that is not the md5
field as your "hash", you can set a field in the Javascript Task using the
rd.setMetaHash(Strings) method.
Javascript Task Example
var base = 'data_csv.'
var hash = rd.getFieldAsStrings(base+'hashcode')[0];
//Get source value
rd.setMetaHash(hash)
Then you can set up the duplication check task:
Related Articles:
Simflofy Integration Job Tasks
Simflofy Administration Properties