Simflofy Integrations
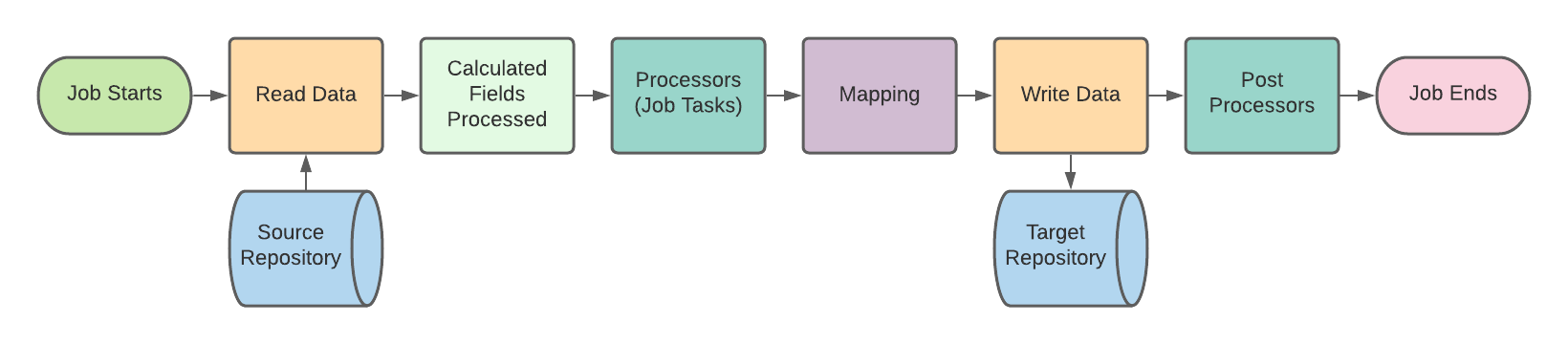
Simflofy has a standard process for performing integrations or indexing, as demonstrated by the steps below.
Create connector instances - This is part of the installation and requires the Admin to create Integrations and Discovery connections for use with the source and target systems. If setting up Federation Content Service and View connections will also be required.
Discovery - Discovery is the 2nd step in the integration process. Here you will create a discovery schema instance,based on the connector's configuration. It includes a list of all object types as well as attributes stored in each. Run discovery to get the schema/content type information from both the source and destination systems.
Create and run jobs - This involves mapping metadata, configuring tasks for any kind of processing that is required (pre-requisite), and any targeted configuration for the source and destination. There are several ways to run jobs and depending on the amount of data the Simflofy Admin will set these up accordingly.
Job Setup and Configurations
The final step in the integration process includes mapping fields from each repo, creating and running the final job.
Event Configuration
Event Rules let you trigger jobs from content service calls. For example, if a file is updated in a source system, an
event can be set up to trigger an index.
Event Job Configurations
Event Job Tutorial
Job Mappings
Simflofy Mapping gives you the ability to map your content types and metadata from one system to another. Before you
start, be sure you are familiar with creating jobs and
discovery. Both are integral to mapping.
- Job Mappings Tutorial - This tutorial explains how mapping works including using calculated fields and mapping templates.
- Mapping Groups - Mapping groups allow you to group job mappings into logical groups that you can then manage together.
- Properties File Discovery - If you ever have the situation where Discovery can't automatically find your fields, but you know they will be there, then you can create your own mappings with a properties file.
- Simflofy Expression Language - Simflofy Expressions are used for calculated fields on the mapping page
Schedule Jobs
Simflofy allows users to schedule integration jobs and job groups to run at a time period that may be more effective for
the servers running them. Jobs can be scheduled to run at set times as well as set intervals. By minutes, hours, days,
weeks ect.
Creating a Scheduled Job
List Jobs
The List jobs page shows the jobs created. There are five available Job Types: Sync,
Simple Migration, Incremental Migration, Event and Polling.
Simflofy Jobs Overview
Job Tasks
This document will walk you through the tasks function in Simflofy. It covers
Adding a task, task pipeline, editing, task group. Click here for the full task
list.
Job Tasks Overview
Run and Monitor Jobs
The Run and Monitor Jobs page is where you can monitor the progress of your integration jobs. From this page you can see
the status of your jobs. How many files have been migrated. When the job was last ran and any errors that might have
occurred during the integration.
Run and Monitor Jobs Overview
Advanced Configurations
PII Detection and Reporting
While doing a document migration or synchronization it may be prudent to check
the document, or it's metadata for PII. You can also crawl you content simply
for PII by using our reporting output connector with any repository connector
that we support.
How to use PII Detection and Reporting
Document Duplication Detection and Reporting
There may be a need to identify duplicate documents in your enterprise and
Simflofy allows you to identify these duplicate documents in a variety of ways.
Identifying Duplicate Documents
Stuck Jobs
If a job is running and the Abort does not stop the job in an appropriate amount
of time, the job can be killed manually through an Admin page.
How to Clear Stuck Jobs
How to View Active Jobs
Simflofy Job Flow
Related Articles:
Integration Connections
Quick Start User Guide
Simflofy Tutorials