Tasks List
The following is an updated list of Job Tasks for Simflofy. Each has its own section for details on its purpose, how and when to use it, and how to configure it.
ACL Converter
This task is for advanced users who wish to write their own ACL Conversion
java code. In order to do this, the class must implement the IACLConverter
Interface. The task must be packaged in the simflofy-admin/WEB-INF/lib folder.
Here are Oracles docs
on how to create a jar file. You will need to first compile the class, then package it.
From there, the task will execute the implementation of the method.
The Map produced will be added to a specific field on each document called "Transformed Permissions".
The task's one field should be the package + class name for your custom class.
Map<String, Set<String>> perms = this.aclConverter.convertACLs(rd.getACL(), outputHelper.isFolder(rd));
rd.setTransformedPermissions(perms);
Any connector with Process ACLS as an option uses the transformed permissions.
Full IACLConverter Class
package com.simflofy.core.common.output.acl;
import java.util.Map;
import java.util.Set;
/**
* @author mlugert
*/
public interface IACLConverter {
/**
* @param rawAcls
* @return Takes a list of ACLs in this format:
* principle=permission1,permission2,permission3
* <p>
* and converts them to a map with the key=principle
* and the set being a list of permissions
* <p>
* Each converter will be specific to a customer/repo
* The permissions will be tranformed from the repo ACLs
* into the output ACLs that the customer wants.
*/
Map<String, Set<String>> convertACLs(String[] rawAcls, boolean isFolder) throws Exception;
}

Alfresco Property Mapping Nodes
Purpose: This task is for getting existing node references in an Alfresco instance, in order to update them, rather than create a new one if the existing file has moved from its original ingestion location.
Use cases: It's used in jobs where the Alfresco Output connector is used. Typically, in incremental or sync jobs, where changes to a file from a source system need to make it to the node it previously integrated to.
How to set up: Provide the query JSON object, which is then sent to Alfresco which will return the matching Alfresco nodeReference, which we'll use to update the document.
Exceptions/requirements: If the query is too vague, and matches more than one node/document, then none of the documents will be updated. The query has to uniquely find a single node/document in Alfresco.

Alfresco Job Run History Nodes
Purpose: Getting the Alfresco Node Reference from the Current Job Run History, in order to update an existing document from a previous Job run in Alfresco, rather than creating a new one.
Use Case: It's used in Incremental or Sync jobs where the Alfresco connector is being used. This task uses the Source Repository ID from the Repository the document is pulled from, in order to find the document in the Job Run History.
Set up: There are no configuration options for this task. It uses the Document's Source Repository ID in order to find the node Reference in Alfresco.
Exception/Requirements: Since the Source Repository ID is used, any source repositories that use a Path Based Source ID will not work if the path of the document changes.
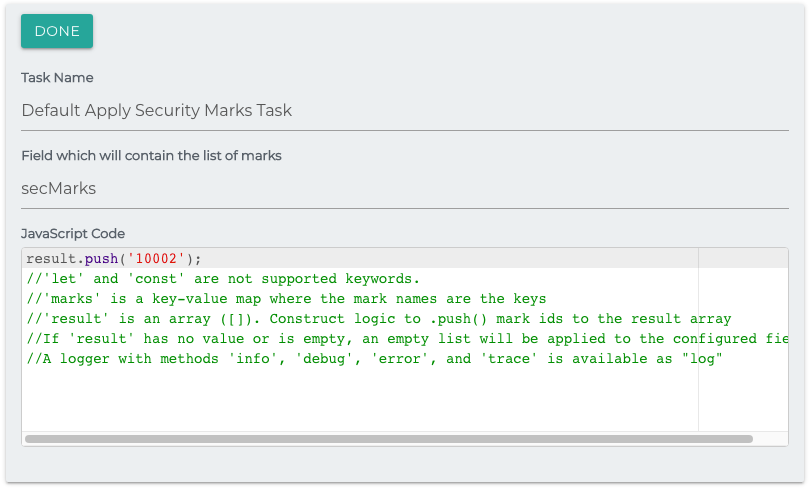
Apply Security Marks
Used to add Security Marks to documents during migration. The task uses javascript to push Security Mark Ids (accessible through the API) to an array called results. These results will be added to the secMarks field on the document. You will still need to map this field to apply them a document in the indexing engine.
AWS Rekognition Image
Detects real world objects in images and adds these labels to the repository document on the field simflofy_ai_labels using the AWS Rekognition system.
For your reference, these are 'MinConfidence' and 'MaxLabels' here. This page is what this task uses.
Task Configuration
- Minimum Threshold: The minimum confidence threshold for labels to return following label detection. Labels with a confidence level lower than this will not be returned.
- Max Number of labels: The maximum number of recognized labels to be returned, by highest confidence.
- Auth conn: Your Amazon AWS credentials
- Max number of labels: The number of labels you want to return

AWS Textract
Extracts text from PNGs, JPGs, and PDFs and stores it on the repository document in the simflofy_ai_text field.
Task Configuration:
- Authentication Connection: Your Amazon AWS credentials
Reference documentation: Amazon Textract
Basic JDBC Job
User Name: JDBC User Name
Password: JDBC Password
Driver Class: The driver for the JDBC database. A number of possible drivers are listed here.
caution
Ensure that your driver jar file is in the simflofy-admin/WEB-INF/lib folder at startup.
JDBC Url: Url to connect to the database. Each type of database uses a different format. Refer to the linked table for formats.
ID Field: The field (without table name) which will be used to name binaries queried from the database.
Query: The query to execute. All results will be added to the document in the format [tableName].[fieldName]
Buffer Binaries to File System
As the name says, this task will buffer files to temporary directory. In this case the value of the System Property java.io.tmpdir. The task takes a timeout which will fail the document if it does not complete staging in the given amount of time. The default is 10 seconds, but for larger files (100+ MB), we recommend 60 seconds.
Clean Array Value To String
Converts a property on a repository document from an array to a String.
Delimiter: The delimiter to place in between values of the Array. If left empty will default to space
Property: The array repository document property to convert into a String. The new String property will have the same name.

CMIS ACL modification
This task is meant to be used with a CMIS Repository connection. It will use the Repository Document id, and gather the current ACL for the document. It will then generate a new ACL based on the parameters. This task establishes a session upon initialization, and keeps it open until the job run is complete.
The principal lists are pipe (|) delimited, to account for LDAP style principals. You will need to know the exact principal ids of the ACEs (Access Control Entries). The task works by cycling through the current ACEs and a series of if-then logic to construct a new ACL.
- User name: CMIS server user name
- Password: CMIS server password
- Connection URL: CMIS server url
- Repository ID: CMIS repository ID
- Pipe (|) delimited list of principals to ignore from each document: A list of principals to ignore and not add modifications to. The 'ignore' list will bypass any modification to a matchingACE and add it directly back to the new ACL.
- Pipe (|) delimited list of principals to remove from each document: A list of principals to be removed from the ACL. The remove list will skip over a matching ACE, leaving it out.
- Pipe (|) delimited list of principals to add to each document: A list of principals to be added to the ACL. The add list is checked separately and will generate a new ACE will the selected permissions.
- Permission to add to the principals: Not ignored ACEs and added ACEs will have this permission added to them in the ACL.

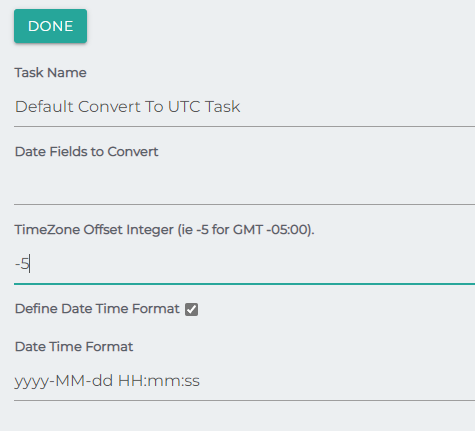
Convert To UTC
As the task name states, will convert date fields to the given format, with the given offset.
Date Fields to Convert: A comma delimited list of repository fields or the output of calculated field.
- If you do not supply field names, the task will attempt to process all the Job's Datetime mappings. Note: only calculated field mappings are available to job processors.
Offset:Timezone offset.
Date Time Format: Final format for the field you're converting.
Define Date Time Format Checkbox: Check to define an output format, uncheck to return default format (i.e. 2019-11-05T16:00:00Z)
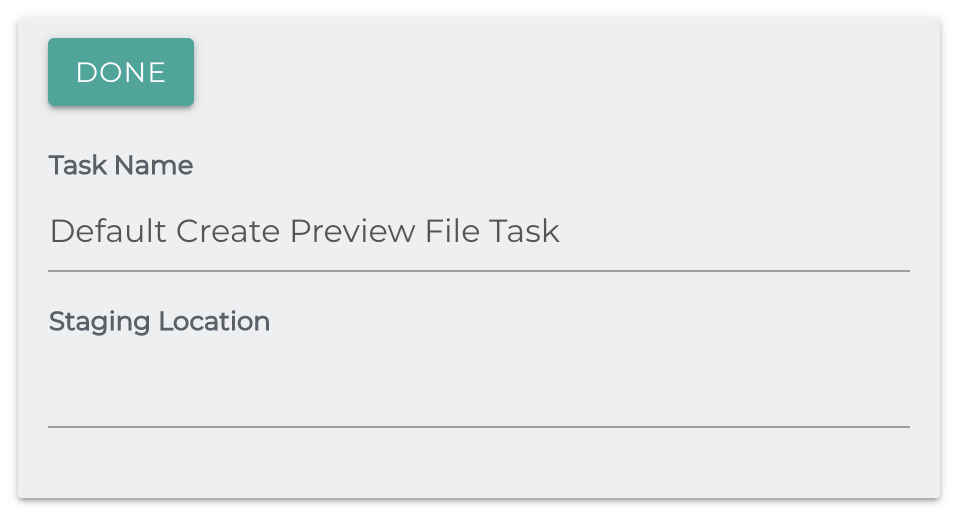
Create Preview File
Creates a thumbnail from an image or video.
Staging Location: The location on the filesystem to place the thumbnail.
Date Based Folder Path
This task takes ones of the date fields on the Repository Document and uses it to generate the parent folder path for the document. This mimics how Alfresco stores its data in the filesystem
Repository Document Field: the field to use for the path - can be any date field
Pattern: The pattern used to break down the date into a folder path
The default is /yyyy/M/dd/kk/mm/ss/
In this case, kk is used for hours.
Example
For the document file.txt, if you set the field to used the modified date '#{rd.modifieddate}'
and the date is 1999-04-20T12:01:23, then your path with the default pattern will be
/1999/4/20/12/01/23/file.txt

Duplication Check
This task checks the chosen field to find duplicate documents.
Field to Compare: The field whose value will be used to check for duplicates. If this value is found in any other document it will be considered a duplicate. Default is the file hash
- If you wish to compare file hashes (a sort of fingerprint for a document), you will need to precede this task with a Hash Generator Task.
Duplication Check Scope: Check all documents, or just the ones associated with this job.
Action: What to do if a document is found. The Document can be skipped, failed, or simply logged.

EML Metadata Extraction
An EML file is an email message saved by an email application, such as Microsoft Outlook or Apple Mail. It contains the content of the message, along with the subject, sender, recipient(s), and date of the message. EML files may also store one or more email attachments, which are files sent with the message.

This task extracts metadata from emails and adds as fields to the repository document. These extracted fields appear as:
Email.Subject: The subject line of the email.
Email.From: The 'from' line of the email.
Email.To: The 'to' line of the email.
Email.Body: The body of the email.
Email.CC: The CC line of the email.
Email.BCC: The BCC line of the email.
Email.EmailList: Space separated list of To, From and CC addresses.
Email.InternetMessageId: The message ID of the email.
Email.Size: The size of the email.
Email.HasAttachments: Whether the email has attachments or not.
Email.Attachments: Comma delimited list of email attachments by name. Blank if none.
Email.AttachmentCount: The number of attachments in this email.
Email.DateTimeSent: The date time the email was sent.
Email.DateTimeCreated: The date time the email was created.
Email.LastModifiedTime: The modified date time of the email.
Email.DateTimeReceived: The date and time the email was received.
Extract Metadata From Path
Path Field: Which field to use to extract metadata. Options are
- Repository ID (for repos that use the entire path as an ID, such as Filesystem, or Amazon S3)
- Parent Path, for repos that don't use paths as ID.
Path Rules: Comma delimited list of rules to extract. The format is [New Field Name]=#{Location}
- Location takes the form of an integer, starting at 0 for the root folder.
- Additionally, 'filename','parent',and 'grandparent' with **quotes included can be used.
Example
For the file
/accounting/healthcare/userName.pdf
and the rules
department=#{0},type=#{'parent'}
department=accounting
type=healthcare

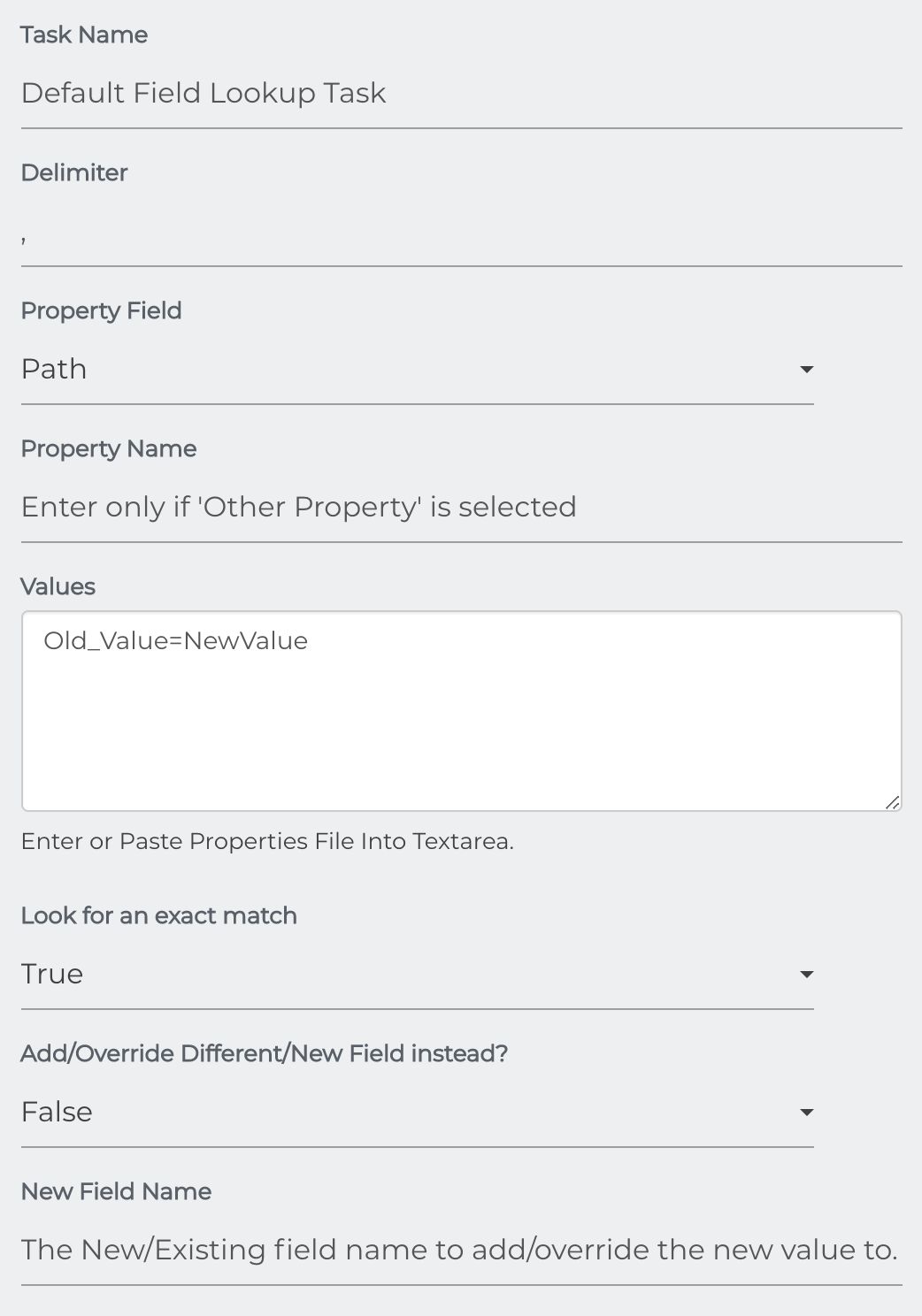
Field Lookup
This task is intended to allow users the ability to perform a look-up operation and update the matching fields of the repository documents. This task was originally created for integrations in which certain field values could only be obtained by importing them from an external source.
Task Name: Name of the Lookup Job Task
Delimiter: Denotes the delimiter character if values are not in list format.
Property Field: Path Uses preset configurations to evaluate values against the path
File Name Uses preset configurations to evaluate values against the file name
Other Property Evaluates a property entered by the user against the given values
Property Name: A specific property entered by the user. This property will be used only if Other Property is selected from the property field dropdown list.
Values: Key=Value listing to be used as the source data for the lookup operation.
Look for an exact match: If set to true, properties that have an exact (whole case) match will be updated. If set to false, properties that contain the entered value(s) will be updated. For instance, if set to true the value 123 will only have a match with 123. If false, a match will be identified if 123 is present in any part of the field and only that portion will be updated with the new value.
Simflofy can utilize any properties that are associated with a repository document. We recommend running a BFS output job with no mappings and Include Un-Mapped Properties set to True. This will generate a xml file similar to the example below and allow you to see what properties are available for your documents:
<properties>
<entry key="document.name">Simflofy Overview.doc</entry>
<entry key="type">document</entry>
<entry key="folderpath">testSimflofy_Setup</entry>
<entry key="document.Culture">en-US</entry>
<entry key="document.Customer">123456</entry>
<entry key="document.Category">training</entry>
</properties>
In the example above you will notice that the document.Customer field has a numerical value associated with it, but not the actual customer name. The task will allow you to import a list of customer IDs along with their associated customer names and update those values as desired.
The updated values will then be available in subsequent job tasks. For instance, you could then use override folder path task to build out a folder structure with the updated values. Using the scenario above, you could build out a folder for each customer by name instead of numerical value.
File Name Extraction
Extracts the file name from another field using regex(Regular Expressions). It will set the file name to the value that matches the regex.
Regex to match: The regex to match and convert to and set as the file name.
Data Field: The repository document field to match the regex on.

Example - Alphanumerics
The pattern for alphanumeric characters is
[a-zA-Z0-9], or if you wish to include underscores \w
To select for non-alphanumeric characters we add the carat (^) before the pattern, so
^[a-zA-Z0-9]
The character simply translates to "Not", so it negates whatever is after it.
Example - Clearing Unwanted Spaces
The pattern \s is regex shorthand for "spaces". If you're worried about tabs, line breaks etc.
add an asterisk (*) after the pattern for what is called "greedy" selection.
Adding this as your regex and setting the replacement as ''
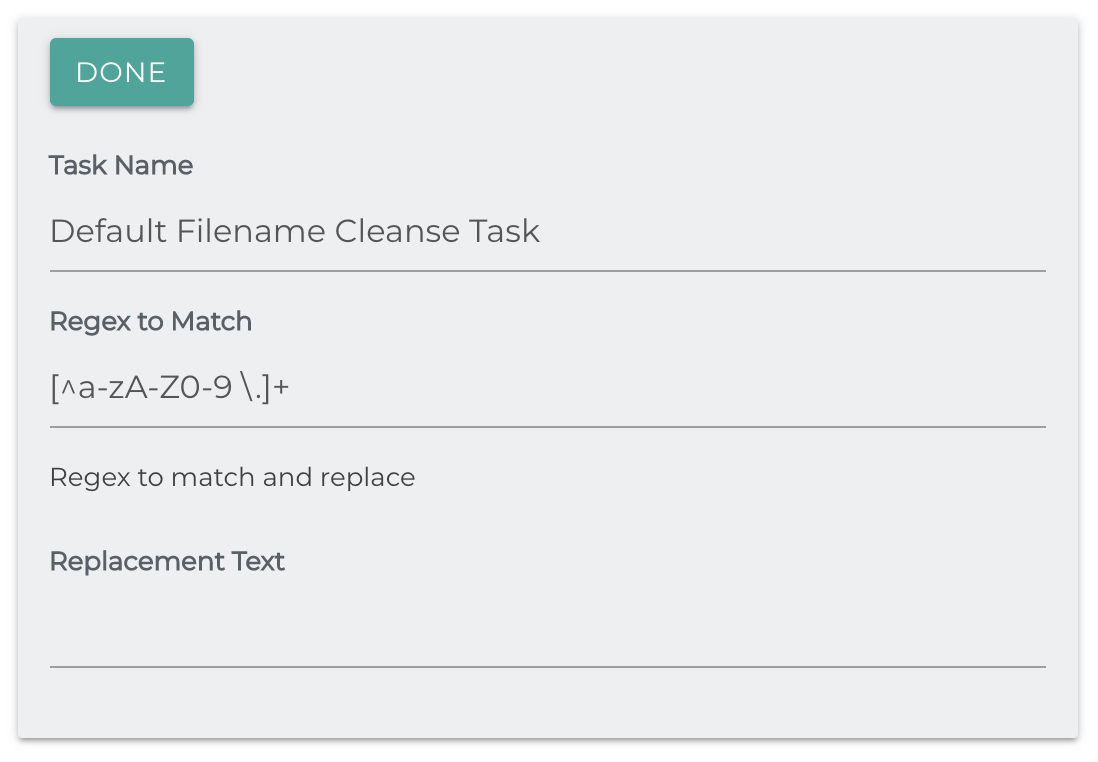
Filename Cleanse
This task uses regex (Regular Expressions) to alter filenames.
Common use cases are clearing unwanted characters, such as whitespace, or non-alphanumeric characters.
Regex to Match: The regex pattern to search for in the filename.
The default value matches any character that isn't a letter, number, space or period an unlimited number of times.
Replacement: Replacement for matches.
Example - Alphanumerics
The pattern for alphanumeric characters is
[a-zA-Z0-9], or if you wish to include underscores \w
To select for non-alphanumeric characters we add the carat (^) before the pattern, so
^[a-zA-Z0-9]
The character simply translates to "Not", so it negates whatever is after it.
Example - Clearing Unwanted Spaces
The pattern \s is regex shorthand for "spaces". If you're worried about tabs, line breaks etc.
add an asterisk (*) after the pattern for what is called "greedy" selection.
Adding this as your regex and setting the replacement as ''
FileNet ACL Modification
Deprecation
This task will be converted to a post-processor in 3.2
The purpose of this task is change the permission lists of integrated documents in the IBM FileNet Repository.
- Authentication Connector ID: The ID of your P8 Authentication connection is available in the Authentications Connection under the Integration menu. You can find it the url of the edit or view page for the connection
- Change List: Pipe (|) delimited list of principals to change from each document.
- Permissions to Change: Access level for the changed permissions.
- Add List: Pipe (|) delimited list of principals to add to each document
- Permissions to Add: The access level to add to the new permissions.
- Removal List: Pipe (|) delimited list of principals to remove from each document.
Note that any permission not added to these lists will be ignored.

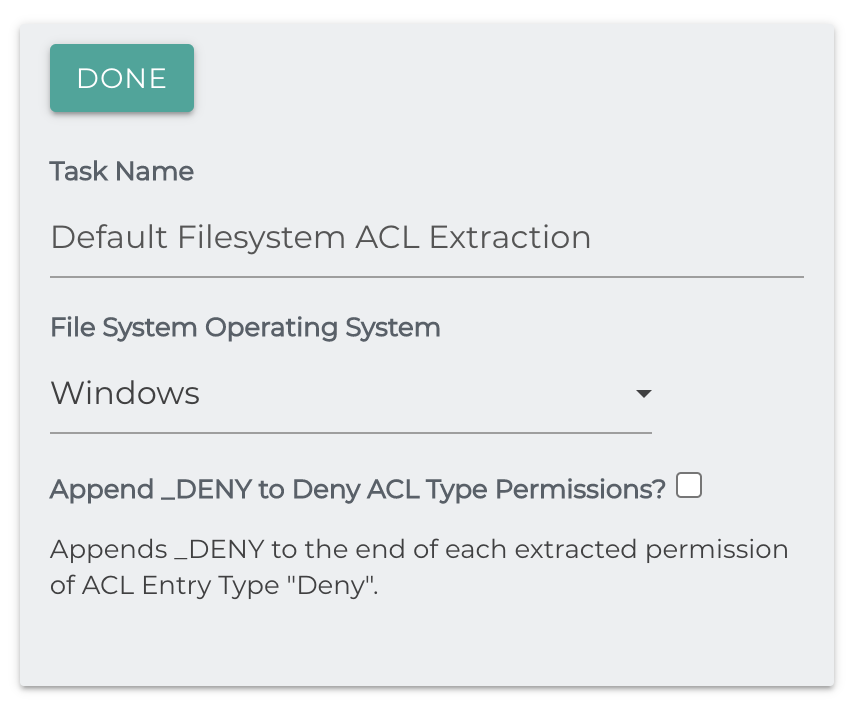
Filesystem ACL Extraction
Extracts ACLs from the Windows or Linux filesystem document and adds them to the repository document.
File System Operating System: The operating system that these files are being read from.
Append _DENY to Deny ACL Type permissions?: Appends _DENY to the
end of an extracted permission if it's of the type DENY, in case you want to
track this later on.
This task will have some different behavior depending on your operating system.
In a POSIX environment (macOS or Linux) permissions may be added as the field
document.permissions with the permissions in a semicolon(;) delimited list, if any exist.
If the filesystem supplies an owner, it will be added as simflofy.owner
Additionally, simflofy will create a permission map of the principals and their permissions. It will set is as the originalPermissions field, so
Map<String, Set<String>> permissions = new Map<>();
//process acls
rd.setOriginalPermissions(permissions);
Finally, if any User Defined File Attributes (extended attributes), they will be added as a semicolon delimited list in the field
simflofy.userattributes
Filter Expression
The filter expression task allows you to remove files based on the expression used. The task has two fields, the task name and the filter expression. The task name is arbitrary but should identify the type of filter you're creating.
Filter Expression
The filter expression can use any of the Simflofy Expression Language components to form simple or more complex expressions for evaluation by Simflofy.
If the expression evaluates to true, the document will continue to be processed.
Example: If you want to exclude the OS level file Thumbs.db in your job, you
can filter those files out using the following statement:
!equalsIgnoreCase('#{rd.filename}', 'Thumbs.db')
The above example will find all the files that have the name 'Thumbs.db' and set the expression to false for the documents. Therefore, all files with the name 'Thumbs.db' will be skipped.

Folder Path Cleanse
This task uses Regular Expressions (regex) to alter Folder Names.Functionally identical to Filename Cleanse Task, except that is changes the document parent path.
Regex to Match: The regex pattern to search for in the Folder Name.
The default value matches any character that isn't a letter, number, space or period an unlimited number of times.
Replacement: Replacement for matches.

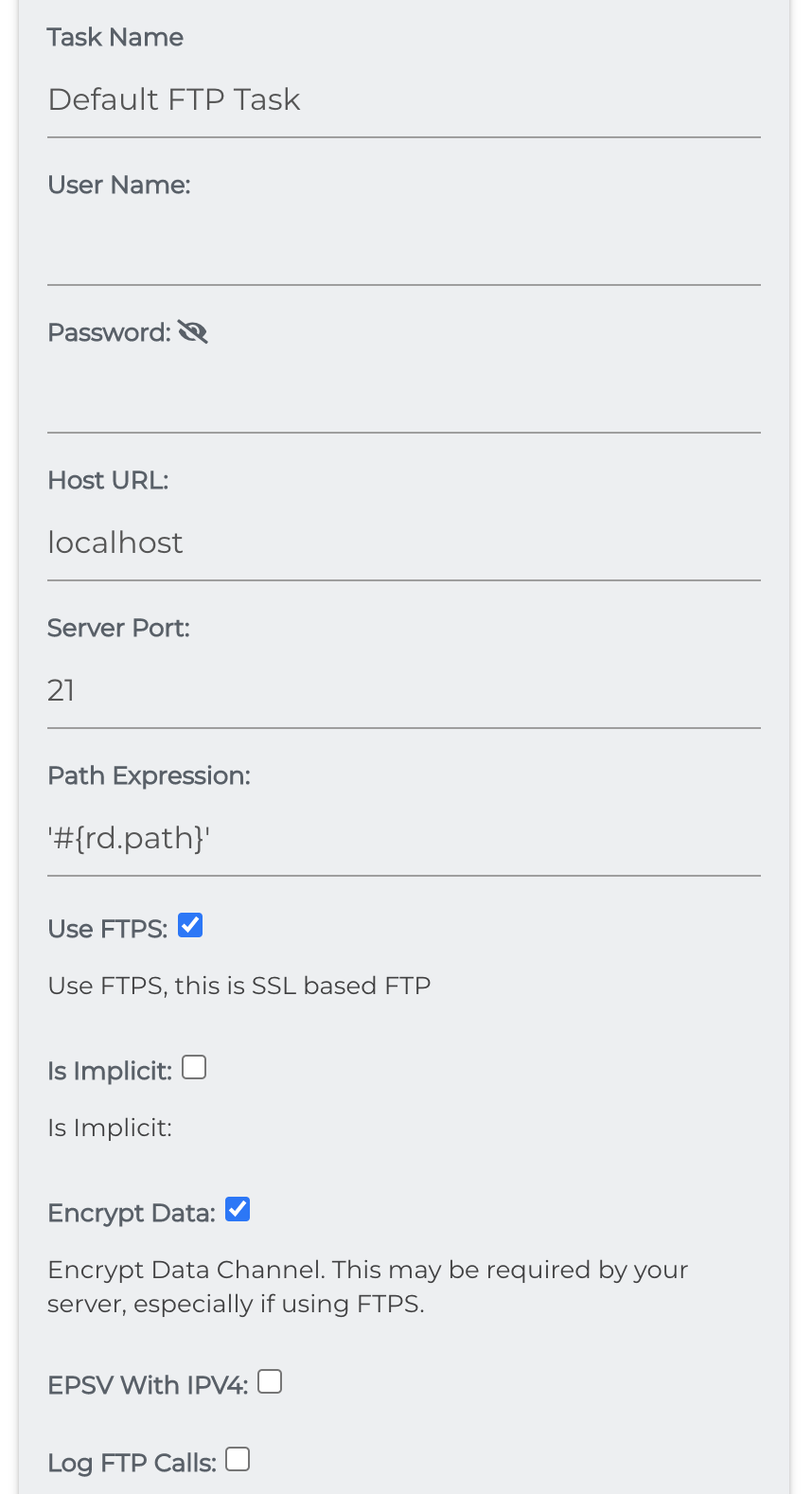
FTP
Sets the binary of a document to a binary found on an FTP server at the location found using the Path Expression.
- Username: The username needed to log in to your FTP server
- Password: The password needed to log in to your FTP server
- Host URL: The URL of the FTP server
- Encrypt Data: Sets whether to encrypt the data connection to the FTP server with TLS. Note that Use FTPS must be checked if you use this.
- Use FTPS: Sets whether to use FTP with SSL protocol.
- Is Implicit: Sets whether to use FTP implicit SSL or FTP explicit SSL
- EPSV With IPV4: Sets whether to use EPSV with IPV4.
- Server Port: The port your FTP server is listening on
- Thread Count: Number of FTP poster threads
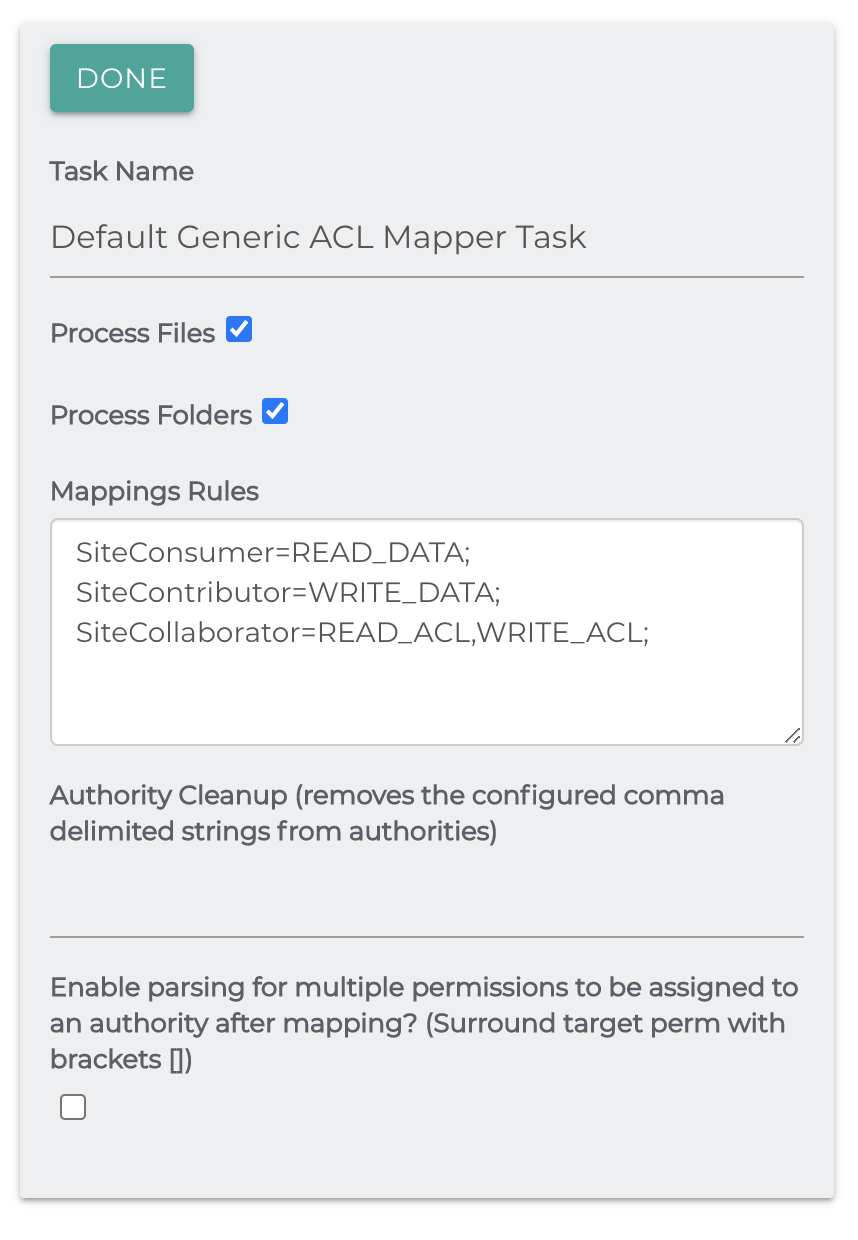
Generic ACL Mapper
The generic ACL mapper job task allows you to create simple rules for matching principles and permissions from one system to another. ACLs will need to be extracted from each document. This task reads the originalPermissions field of the document and sets the transformedPermissions field.
Limited Usage
Only the Azure Blob, CMIS, and Alfresco Connectors can use this task. For all other acl mapping, a Javascript task or ACL Converter Task is required
- Process Files and Process Folders tells the task what to process.
- Mapping Rules: These rules will map the role/permissions on the left with the ones you want to match on the right.
- Permissions on the right will be from the source and those on the left will be for the target.
- Both side of a rule can be a comma delimited list.
- Each rule must end with a semicolon (;)
- Authority Cleanup: A comma delimited list of principals to remove as part of the task.
- Enabling parsing: Enable parsing for multiple permissions to be assigned to an authority after mapping?
- For example, [Write]=WRITE_DATA with this box checked will allow 'Write' to be added on as an extra permission to an authority's newly mapped permissions.
Google Vision Image Labels
Detects real world objects in images and adds these labels to the repository document on the field simflofy_ai_labels using Google Vision.
Max Number of labels: The maximum number of recognized labels to be returned
Authentication connection: Your authentication connection for Google. You can find it in the url while edit or view page for the connection

Google Vision Text Extraction
Extracts text from .tiff, .pdf and .gif files and stores it on the repository document in the simflofy_ai_texts field.
Authentication Connector: Your authentication connection for Google You can find it in the url while edit or view page for the connection

Hash Value Generator
Creates a hash of the document content and sets it on the repository document. Can be used in tandem with the Duplication Check Task to find duplicates.
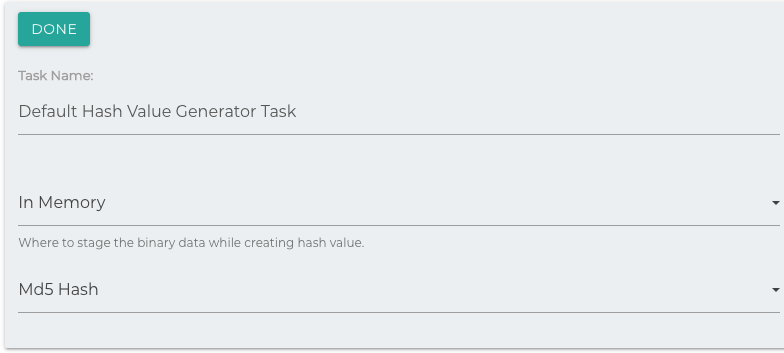
Staging: Where to stage the data locally, while creating the MD5 Hash.
Hash Type: The type of hash to use. MD5 is the default hash, but SHA hashes are available
HTML to PDF
This task takes a single argument, which is a file path to an XHTML stylesheet ( *.xsl).
The binary stream is taken from each repository document and converts it to a pdf using the template.
Here's a default stylesheet to save and try.
Less complex examples can be found here
Sample XSL Style Sheet
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform"
xmlns:fo="http://www.w3.org/1999/XSL/Format" xmlns:xhtml="http://www.w3.org/1999/xhtml"
exclude-result-prefixes="xhtml">
<xsl:output method="xml" version="1.0" standalone="yes" omit-xml-declaration="yes"
encoding="utf-8" media-type="text/xml" indent="yes"/>
<xsl:strip-space elements="*"/>
<xsl:preserve-space elements="xhtml:listing listing xhtml:plaintext plaintext xhtml:pre pre xhtml:samp samp"/>
<xsl:param name="font-size" select="''"/>
<xsl:param name="font.symbol" select="'Arial Unicode MS'"/>
<xsl:template name="common-atts">
<xsl:copy-of select="@id|@color|@height|@width|@xml:lang"/>
<xsl:if test="@align"><xsl:attribute name="text-align"><xsl:value-of select="@align"/></xsl:attribute></xsl:if>
<xsl:if test="@nowrap"><xsl:attribute name="wrap-option">no-wrap</xsl:attribute></xsl:if>
</xsl:template>
<xsl:template match="xhtml:html|html">
<fo:root>
<fo:layout-master-set>
<fo:simple-page-master master-name="page">
<fo:region-body margin=".75in .75in .75in .75in"/>
<fo:region-before extent=".5in"/>
<fo:region-after extent=".5in"/>
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence master-reference="page">
<fo:static-content flow-name="xsl-region-before">
<fo:block display-align="after" padding-before=".2in" text-align="center" font-size="9pt">
<xsl:apply-templates select="xhtml:head/xhtml:title|head/title"/>
</fo:block>
</fo:static-content>
<fo:static-content flow-name="xsl-region-after">
<fo:block display-align="before" text-align="center" font-size="8pt">
<xsl:text>page </xsl:text>
<fo:page-number/><xsl:text> of </xsl:text>
<fo:page-number-citation ref-id="__END__"/>
</fo:block>
</fo:static-content>
<xsl:apply-templates/>
</fo:page-sequence>
</fo:root>
</xsl:template>
<xsl:template match="xhtml:title|title">
<fo:block><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:basefont|basefont">
<xsl:copy-of select="@color"/>
<xsl:choose>
<xsl:when test="@size=1"><xsl:attribute name="font-size">xx-small</xsl:attribute></xsl:when>
<xsl:when test="@size=2"><xsl:attribute name="font-size">x-small</xsl:attribute></xsl:when>
<xsl:when test="@size=3"><xsl:attribute name="font-size">small</xsl:attribute></xsl:when>
<xsl:when test="@size=4"><xsl:attribute name="font-size">medium</xsl:attribute></xsl:when>
<xsl:when test="@size=5"><xsl:attribute name="font-size">large</xsl:attribute></xsl:when>
<xsl:when test="@size=6"><xsl:attribute name="font-size">x-large</xsl:attribute></xsl:when>
<xsl:when test="@size=7"><xsl:attribute name="font-size">xx-large</xsl:attribute></xsl:when>
</xsl:choose>
<xsl:if test="@face"><xsl:attribute name="font-family"><xsl:value-of select="@face"/></xsl:attribute></xsl:if>
</xsl:template>
<xsl:template match="xhtml:body|body">
<fo:flow flow-name="xsl-region-body">
<xsl:call-template name="common-atts"/>
<xsl:apply-templates select="//basefont[1]"/>
<xsl:if test="$font-size"><xsl:attribute name="font-size"><xsl:value-of select="$font-size"/></xsl:attribute></xsl:if>
<xsl:apply-templates/>
<fo:block id="__END__"/>
</fo:flow>
</xsl:template>
<xsl:template match="xhtml:head|head|xhtml:applet|applet|xhtml:area|area|xhtml:base|base
|xhtml:bgsound|bgsound|xhtml:embed|embed|xhtml:frame|frame|xhtml:frameset|frameset|xhtml:iframe|iframe
|xhtml:ilayer|ilayer|xhtml:layer|layer|xhtml:input[@type='hidden']|input[@type='hidden']
|xhtml:isindex|isindex|xhtml:link|link|xhtml:map|map|xhtml:meta|meta|xhtml:object|object|xhtml:param|param
|xhtml:ruby|ruby|xhtml:rt|rt|xhtml:script|script|xhtml:spacer|spacer|xhtml:style|style|xhtml:wbr|wbr
|xhtml:xml|xml|xhtml:xmp|xmp"/>
<xsl:template match="comment">
<xsl:comment><xsl:apply-templates/></xsl:comment>
</xsl:template>
<xsl:template match="processing-instruction()">
<xsl:copy-of select="."/>
</xsl:template>
<!-- Links and Media -->
<xsl:template match="xhtml:a|a">
<fo:inline><xsl:call-template name="common-atts"/>
<xsl:if test="@name and not(@id)">
<xsl:attribute name="id"><xsl:value-of select="@name"/></xsl:attribute>
</xsl:if>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:a[@href]|a[@href]">
<fo:basic-link color="blue" text-decoration="underline">
<xsl:if test="@type"><xsl:attribute name="content-type"><xsl:value-of select="@type"/></xsl:attribute></xsl:if>
<xsl:choose>
<xsl:when test="starts-with(@href,'#')">
<xsl:attribute name="internal-destination"><xsl:value-of select="substring-after(@href,'#')"/></xsl:attribute>
</xsl:when>
<xsl:otherwise>
<xsl:attribute name="external-destination">
<xsl:text>url('</xsl:text>
<xsl:value-of select="concat(//base/@href,@href)"/>
<xsl:text>')</xsl:text>
</xsl:attribute>
</xsl:otherwise>
</xsl:choose>
<xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:basic-link>
</xsl:template>
<xsl:template match="xhtml:img|img|xhtml:input[@type='image']|input[@type='image']">
<fo:external-graphic content-type="{@type}" src="{concat(//base/@href,@src)}">
<xsl:call-template name="common-atts"/>
</fo:external-graphic>
</xsl:template>
<xsl:template match="xhtml:object[starts-with(@type,'image/')]|object[starts-with(@type,'image/')]">
<fo:external-graphic content-type="{@type}" src="{concat(//base/@href,@data)}">
<xsl:call-template name="common-atts"/>
</fo:external-graphic>
</xsl:template>
<!-- Tables -->
<xsl:template match="xhtml:table">
<xsl:apply-templates select="caption"/>
<fo:table width="100%"><xsl:call-template name="common-atts"/>
<xsl:apply-templates select="colgroup|col"/>
<xsl:variable name="tr1" select="(xhtml:tr|xhtml:thead/xhtml:tr|xhtml:tbody/xhtml:tr|xhtml:tfoot/xhtml:tr)[1]"/>
<xsl:variable name="cols" select="xhtml:colgroup/xhtml:col|xhtml:col"/>
<xsl:call-template name="mock-col">
<xsl:with-param name="cols" select="(count($tr1/xhtml:*[not(@colspan)])+sum($tr1/xhtml:*/@colspan))
-(count($cols[not(@colspan)])+sum($cols/@colspan))"/>
</xsl:call-template>
<xsl:apply-templates select="xhtml:thead|xhtml:tfoot|xhtml:tbody"/>
<xsl:if test="xhtml:tr">
<fo:table-body><xsl:call-template name="common-atts"/>
<xsl:apply-templates select="xhtml:tr"/>
</fo:table-body>
</xsl:if>
</fo:table>
</xsl:template>
<xsl:template match="table">
<xsl:apply-templates select="caption"/>
<fo:table width="100%"><xsl:call-template name="common-atts"/>
<xsl:apply-templates select="colgroup|col"/>
<xsl:variable name="tr1" select="(tr|thead/tr|tbody/tr|tfoot/tr)[1]"/>
<xsl:variable name="cols" select="colgroup/col|col"/>
<xsl:call-template name="mock-col">
<xsl:with-param name="cols" select="(count($tr1/*[not(@colspan)])+sum($tr1/*/@colspan))
-(count($cols[not(@colspan)])+sum($cols/@colspan))"/>
</xsl:call-template>
<xsl:apply-templates select="thead|tfoot|tbody"/>
<xsl:if test="tr">
<fo:table-body><xsl:call-template name="common-atts"/>
<xsl:apply-templates select="tr"/>
</fo:table-body>
</xsl:if>
</fo:table>
</xsl:template>
<xsl:template match="xhtml:colgroup|colgroup">
<xsl:apply-templates/>
</xsl:template>
<xsl:template name="mock-col">
<xsl:param name="cols" select="1"/>
<xsl:if test="$cols>0">
<fo:table-column column-width="proportional-column-width(1)"/>
<xsl:call-template name="mock-col">
<xsl:with-param name="cols" select="$cols -1"/>
</xsl:call-template>
</xsl:if>
</xsl:template>
<xsl:template match="xhtml:col|col">
<fo:table-column><xsl:call-template name="common-atts"/>
<xsl:if test="@span">
<xsl:attribute name="number-columns-spanned"><xsl:value-of select="@span"/></xsl:attribute>
</xsl:if>
<xsl:choose>
<xsl:when test="@width">
<xsl:attribute name="column-width"><xsl:value-of select="@width"/></xsl:attribute>
</xsl:when>
<xsl:otherwise>
<xsl:attribute name="column-width">proportional-column-width(1)</xsl:attribute>
</xsl:otherwise>
</xsl:choose>
</fo:table-column>
</xsl:template>
<xsl:template match="xhtml:tbody|tbody">
<fo:table-body><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:table-body>
</xsl:template>
<xsl:template match="xhtml:thead|thead">
<fo:table-header><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:table-header>
</xsl:template>
<xsl:template match="xhtml:tfoot|tfoot">
<fo:table-footer><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:table-footer>
</xsl:template>
<xsl:template match="xhtml:tr|tr">
<fo:table-row><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:table-row>
</xsl:template>
<xsl:template match="xhtml:th|th">
<fo:table-cell font-weight="bold" padding=".1em"><xsl:call-template name="common-atts"/>
<xsl:if test="@colspan">
<xsl:attribute name="number-columns-spanned"><xsl:value-of select="@colspan"/></xsl:attribute>
</xsl:if>
<xsl:if test="@rowspan">
<xsl:attribute name="number-rows-spanned"><xsl:value-of select="@rowspan"/></xsl:attribute>
</xsl:if>
<fo:block>
<xsl:if test="parent::xhtml:tr/parent::xhtml:thead|parent::tr/parent::thead">
<xsl:attribute name="text-align">center</xsl:attribute>
</xsl:if>
<xsl:apply-templates/>
</fo:block>
</fo:table-cell>
</xsl:template>
<xsl:template match="xhtml:td|td">
<fo:table-cell padding=".1em"><xsl:call-template name="common-atts"/>
<xsl:if test="@colspan">
<xsl:attribute name="number-columns-spanned"><xsl:value-of select="@colspan"/></xsl:attribute>
</xsl:if>
<xsl:if test="@rowspan">
<xsl:attribute name="number-rows-spanned"><xsl:value-of select="@rowspan"/></xsl:attribute>
</xsl:if>
<fo:block>
<xsl:apply-templates/>
</fo:block>
</fo:table-cell>
</xsl:template>
<!-- Lists -->
<xsl:template match="xhtml:dd|dd">
<fo:list-item><xsl:call-template name="common-atts"/>
<fo:list-item-label><fo:block/></fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</fo:list-item-body>
</fo:list-item>
</xsl:template>
<xsl:template match="xhtml:dl|dl">
<fo:list-block provisional-label-separation=".2em" provisional-distance-between-starts="3em">
<xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:list-block>
</xsl:template>
<xsl:template match="xhtml:dt|dt">
<fo:list-item><xsl:call-template name="common-atts"/>
<fo:list-item-label><fo:block/></fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</fo:list-item-body>
</fo:list-item>
</xsl:template>
<xsl:template match="xhtml:ol|ol">
<fo:list-block provisional-label-separation=".2em"
provisional-distance-between-starts="{string-length(count(li))*.9+.6}em">
<xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:list-block>
</xsl:template>
<xsl:template match="xhtml:ol/xhtml:li|ol/li">
<fo:list-item><xsl:call-template name="common-atts"/>
<fo:list-item-label end-indent="label-end()">
<fo:block text-align="end">
<xsl:variable name="value">
<xsl:choose>
<xsl:when test="@value"><xsl:value-of select="@value"/></xsl:when>
<xsl:otherwise><xsl:number/></xsl:otherwise>
</xsl:choose>
</xsl:variable>
<xsl:choose>
<xsl:when test="@type='I'"><xsl:number format="I" value="$value"/></xsl:when>
<xsl:when test="@type='A'"><xsl:number format="A" value="$value"/></xsl:when>
<xsl:when test="@type='i'"><xsl:number format="i" value="$value"/></xsl:when>
<xsl:when test="@type='a'"><xsl:number format="a" value="$value"/></xsl:when>
<xsl:when test="parent::xhtml:ol/@type='I' or parent::ol/@type='I'"><xsl:number format="I" value="$value"/></xsl:when>
<xsl:when test="parent::xhtml:ol/@type='A' or parent::ol/@type='I'"><xsl:number format="A" value="$value"/></xsl:when>
<xsl:when test="parent::xhtml:ol/@type='i' or parent::ol/@type='I'"><xsl:number format="i" value="$value"/></xsl:when>
<xsl:when test="parent::xhtml:ol/@type='a' or parent::ol/@type='I'"><xsl:number format="a" value="$value"/></xsl:when>
<xsl:otherwise><xsl:number format="1" value="$value"/></xsl:otherwise>
</xsl:choose>
<xsl:text>.</xsl:text>
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</fo:list-item-body>
</fo:list-item>
</xsl:template>
<xsl:template match="xhtml:ul|ul|xhtml:menu|menu">
<fo:list-block provisional-label-separation=".2em" provisional-distance-between-starts="1.6em">
<xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:list-block>
</xsl:template>
<xsl:template match="xhtml:ul/xhtml:li|ul/li|xhtml:menu/xhtml:li|menu/li">
<fo:list-item><xsl:call-template name="common-atts"/>
<fo:list-item-label end-indent="label-end()">
<fo:block text-align="end">
<fo:inline font-family="{$font.symbol}">
<xsl:choose>
<xsl:when test="@type='square'"><xsl:text disable-output-escaping="yes">&#x25AA;</xsl:text></xsl:when>
<xsl:when test="@type='circle'"><xsl:text disable-output-escaping="yes">&#x25CB;</xsl:text></xsl:when>
<xsl:when test="parent::xhtml:ul/@type='square' or parent::ul/@type='square'">
<xsl:text disable-output-escaping="yes">&#x25AA;</xsl:text>
</xsl:when>
<xsl:when test="parent::xhtml:ul/@type='circle' or parent::ul/@type='square'">
<xsl:text disable-output-escaping="yes">&#x25CB;</xsl:text>
</xsl:when>
<xsl:otherwise><xsl:text disable-output-escaping="yes">&#x2022;</xsl:text></xsl:otherwise>
</xsl:choose>
</fo:inline>
</fo:block>
</fo:list-item-label>
<fo:list-item-body start-indent="body-start()">
<fo:block>
<xsl:apply-templates/>
</fo:block>
</fo:list-item-body>
</fo:list-item>
</xsl:template>
<!-- Blocks -->
<xsl:template match="xhtml:address|address">
<fo:block font-style="italic"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:blockquote|blockquote">
<fo:block space-before="1em" space-after="1em" start-indent="3em" end-indent="3em">
<xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:br|br">
<fo:block white-space="pre"><xsl:call-template name="common-atts"/>
<xsl:text disable-output-escaping="yes">&#10;</xsl:text>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:caption|caption">
<fo:block keep-with-next="always" text-align="center">
<xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:center|center">
<fo:block text-align="center">
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:div|div|xhtml:multicol|multicol|xhtml:noembed|noembed|xhtml:noframes|noframes
|xhtml:nolayer|nolayer|xhtml:noscript|noscript">
<fo:block><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:h1|h1">
<fo:block font-size="180%" font-weight="bold"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:h2|h2">
<fo:block font-size="160%" font-weight="bold"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:h3|h3">
<fo:block font-size="140%" font-weight="bold"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:h4|h4">
<fo:block font-size="120%" font-weight="bold"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:h5|h5">
<fo:block font-size="110%" font-weight="bold"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:h6|h6|xhtml:legend|legend">
<fo:block font-weight="bold"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:hr|hr">
<fo:leader leader-pattern="rule" rule-style="groove">
<xsl:if test="@size">
<xsl:attribute name="rule-thickness"><xsl:value-of select="@size"/><xsl:text>pt</xsl:text></xsl:attribute>
</xsl:if>
</fo:leader>
</xsl:template>
<xsl:template match="xhtml:listing|listing|xhtml:plaintext|plaintext|xhtml:pre|pre|xhtml:samp|samp">
<fo:block white-space="pre"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:p|p">
<fo:block space-before=".6em" space-after=".6em"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<!-- Inlines -->
<xsl:template match="xhtml:abbr|abbr|xhtml:acronym|acronym">
<fo:inline><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
<xsl:text> (</xsl:text>
<xsl:value-of select="@title"/>
<xsl:text>)</xsl:text>
</xsl:template>
<xsl:template match="xhtml:b|b|xhtml:strong|strong">
<fo:inline font-weight="bold"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:bdo|bdo">
<fo:bidi-override direction="{@dir}"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:bidi-override>
</xsl:template>
<xsl:template match="xhtml:big|big">
<fo:inline font-size="larger"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:blink|blink|xhtml:marquee|marquee">
<fo:inline background-color="yellow"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:cite|cite|xhtml:dfn|dfn|xhtml:em|em|xhtml:i|i|xhtml:var|var">
<fo:inline font-style="italic"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:code|code|xhtml:kbd|kbd|xhtml:tt|tt">
<fo:inline font-family="monospace"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:del|del|xhtml:s|s|xhtml:strike|strike">
<fo:inline text-decoration="line-through"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:font|font">
<fo:inline><xsl:call-template name="common-atts"/>
<xsl:choose>
<xsl:when test="@size=1"><xsl:attribute name="font-size">xx-small</xsl:attribute></xsl:when>
<xsl:when test="@size=2"><xsl:attribute name="font-size">x-small</xsl:attribute></xsl:when>
<xsl:when test="@size=3"><xsl:attribute name="font-size">small</xsl:attribute></xsl:when>
<xsl:when test="@size=4"><xsl:attribute name="font-size">medium</xsl:attribute></xsl:when>
<xsl:when test="@size=5"><xsl:attribute name="font-size">large</xsl:attribute></xsl:when>
<xsl:when test="@size=6"><xsl:attribute name="font-size">x-large</xsl:attribute></xsl:when>
<xsl:when test="@size=7"><xsl:attribute name="font-size">xx-large</xsl:attribute></xsl:when>
</xsl:choose>
<xsl:if test="@face"><xsl:attribute name="font-family"><xsl:value-of select="@face"/></xsl:attribute></xsl:if>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:ins|ins|xhtml:u|u">
<fo:inline text-decoration="underline"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:nowrap|nowrap">
<fo:inline wrap-option="no-wrap"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:q|q">
<fo:inline><xsl:call-template name="common-atts"/>
<xsl:text disable-output-escaping="yes">&#x201C;</xsl:text>
<xsl:apply-templates/>
<xsl:text disable-output-escaping="yes">&#x201D;</xsl:text>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:q|q[starts-with(.,'"') or starts-with(.,'“') or starts-with(.,'‟')]">
<fo:inline><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:small|small">
<fo:inline font-size="smaller"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:span|span">
<fo:inline><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:sub|sub">
<fo:inline baseline-shift="sub"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:sup|sup">
<fo:inline baseline-shift="super"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<!-- Forms -->
<xsl:template match="xhtml:button|button">
<fo:block background-color="silver" border="3pt outset silver" text-align="center" width="auto">
<xsl:call-template name="common-atts"/>
<xsl:text> </xsl:text>
<xsl:apply-templates/>
<xsl:text> </xsl:text>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:fieldset|fieldset">
<fo:block border="1pt groove gray"><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:form|form">
<fo:block><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:input|input"><!-- default input is text (also handles password & file) -->
<fo:leader leader-pattern="rule"><xsl:call-template name="common-atts"/>
<xsl:attribute name="leader-length">
<xsl:choose>
<xsl:when test="@size"><xsl:value-of select="@size"/><xsl:text>em</xsl:text></xsl:when>
<xsl:otherwise>10em</xsl:otherwise>
</xsl:choose>
</xsl:attribute>
</fo:leader>
</xsl:template>
<xsl:template match="xhtml:input[@type='checkbox']|input[@type='checkbox']">
<fo:inline font-family="{$font.symbol}" font-size="larger"><xsl:call-template name="common-atts"/>
<xsl:choose>
<xsl:when test="@checked"><xsl:text disable-output-escaping="yes">&#x2611;</xsl:text></xsl:when>
<xsl:otherwise><xsl:text disable-output-escaping="yes">&#x2610;</xsl:text></xsl:otherwise>
</xsl:choose>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:input[@type='radio']|input[@type='radio']">
<fo:inline font-family="{$font.symbol}" font-size="larger"><xsl:call-template name="common-atts"/>
<xsl:choose>
<xsl:when test="@checked"><xsl:text disable-output-escaping="yes">&#x25C9;</xsl:text></xsl:when>
<xsl:otherwise><xsl:text disable-output-escaping="yes">&#x25CB;</xsl:text></xsl:otherwise>
</xsl:choose>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:input[@type='button' or @type='submit' or @type='reset']
|input[@type='button' or @type='submit' or @type='reset']">
<fo:block background-color="silver" border="3pt outset silver" text-align="center" width="auto">
<xsl:call-template name="common-atts"/>
<xsl:text> </xsl:text>
<xsl:choose>
<xsl:when test="@value"><xsl:value-of select="@value"/></xsl:when>
<xsl:otherwise><xsl:value-of select="@type"/></xsl:otherwise>
</xsl:choose>
<xsl:text> </xsl:text>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:label|label">
<fo:inline><xsl:call-template name="common-atts"/>
<xsl:apply-templates/>
</fo:inline>
</xsl:template>
<xsl:template match="xhtml:select[@size=1]|select[@size=1]">
<fo:leader leader-pattern="rule" leader-length="10em">
<xsl:call-template name="common-atts"/>
</fo:leader>
</xsl:template>
<xsl:template match="xhtml:select|select">
<fo:block><xsl:call-template name="common-atts"/>
<xsl:if test="@size">
<xsl:attribute name="height"><xsl:value-of select="@size"/><xsl:text>em</xsl:text></xsl:attribute>
</xsl:if>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:optgroup|optgroup">
<fo:block font-style="italic" font-weight="bold"><xsl:call-template name="common-atts"/>
<xsl:value-of select="@label"/>
</fo:block>
<xsl:apply-templates/>
</xsl:template>
<xsl:template match="xhtml:option|option">
<fo:block><xsl:call-template name="common-atts"/>
<xsl:if test="parent::xhtml:optgroup|parent::optgroup">
<xsl:attribute name="start-indent">1em</xsl:attribute>
</xsl:if>
<xsl:choose>
<xsl:when test="@label"><xsl:value-of select="@label"/></xsl:when>
<xsl:otherwise><xsl:apply-templates/></xsl:otherwise>
</xsl:choose>
</fo:block>
</xsl:template>
<xsl:template match="xhtml:textarea|textarea">
<fo:block border="2pt inset silver" height="{@rows}em" width="{@cols}em">
<xsl:choose>
<xsl:when test="node()"><xsl:apply-templates/></xsl:when>
<xsl:otherwise><xsl:text> </xsl:text></xsl:otherwise>
</xsl:choose>
</fo:block>
</xsl:template>
</xsl:stylesheet>
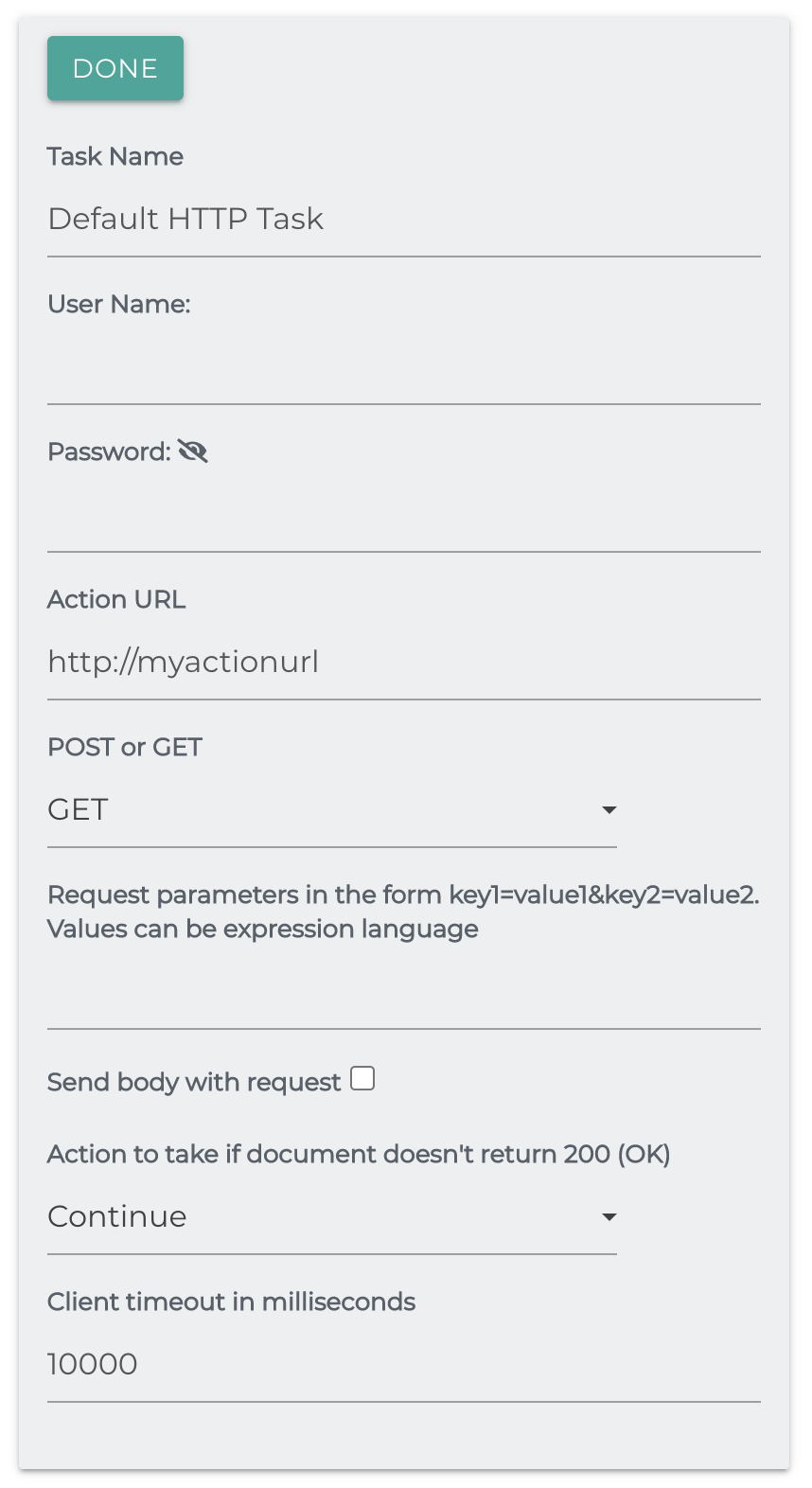
HTTP
The purpose of this task is to execute a GET or POST HTTP call for each repository document. If the status is 200 (OK), then processing will continue,
if not, the document will be skipped.
- Username/Password Credentials to access the endpoint
- Action URL: The endpoint being contacted, without parameters
- POST or GET: Selects the HTTP Method
- Request parameters: In the form of param1=value1¶m2=value2
- The 'values' can be dynamically created using the Simflofy Expression Language
- Action to take if the call does not return 200(OK): Continue, Skip or Fail are the options
- Timeout in milliseconds: How long to wait for the call to execute before attempting to continue.
- If the timeout is reached, the action selected will be used.
IBM Watson Natural Language Classification
Uses IBM Watson Natural Language classifier to analyze and label text into categories. This uses Watson's Natural Language Classifier apis
- The IAM API Key for IBM Cloud. See instructions here on how to get it.
- The Classifier ID The ID of you classifier, created in Watson.
- Field to process If left blank, the task will search for the field 'content'
- Field to store the Watson response. If left blank, the field name will be 'nlc'.
- Comma delimited list of file extensions Which content types to process or leave blank to process all.

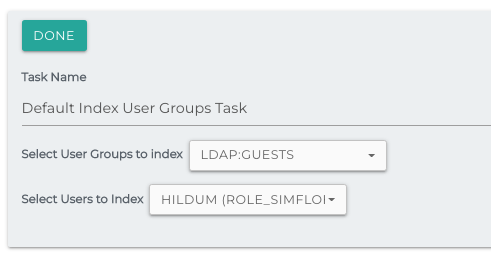
Index User Groups
Used for Search Security to index user and group information onto each document.
Select User Groups To Index: The selected user groups will be added to the field simflofyUserGroups as well as adding a mapping.
Select Users to Index: The selected users will be to the field simflofyUsers as well as adding a mapping.
JavaScript Processing
Simflofy's JavaScript Task allows you to run JavaScript against a repository document during processing. The task utilizes Java's Nashorn engine, which uses the ECMA 5.1 specification to execute the JavaScript against the native Java API. Currently, only one root object is exposed called rd (repository document). Any method that can be called against the repository document can be called using JavaScript syntax. Fields that are also available:
Variable Name : Variable
The Job ID : jobId
The Job Run ID : jobRunId
Logger : log
info
In order to use javascript logging, you will need to set the log
appendercom.simflofy.tasks to Info Debug or Trace. This can be done in Admin
: Logging : Log Levels
Output from the logger methods (i.e. log.info(),
log.debug(), etc.) can be found in the simflofy-admin.log file.
The variable result is automatically declared in each run of the javascript task, and its return value can be used to control which documents continue processing.
The task only supports single quotes for strings. Double quotes will cause errors due to how the content of the script is saved to the database.
Below is an example of failing and skipping documents based on their content type.
Return Value : Status
'c' : Pass
'f' : Fail
's' : Skip
Here are some of the methods the **rd** objects supports:
addSingleField(String, Object)
addArrayField(String, Object[])
addSingleDateField(String, Date)
addDateArrayField(String, Date[])
getCreatedDate()
getFileLength()
getFileName()
getLastAccessedDate()
getMd5()
getModifiedDate()
getPath()
setFileName(String)
setPath(String)
setModifiedDate(Date)
getDocumentField(String) - Produces a DocumentField object with the following methods. Returns null if the field is not present.
getFieldName()
getFieldValue()
- Ex.
rd.getDocumentField('myfield').getFieldValue();
- Ex.
isFieldValueArray() - Check if the value of the field is an array
getFieldValueAsArray() - Return the field value as an array of Objects (even single values)
getFieldType() - Return the data type of the field
toJSONObject() - returns a JSON Object containing the keys "name","type","value"
getDocumentFieldWithLowerCase(String) - Case insensitive version of getDocumentField()
getFieldAsStringHolder(String) - Returns a FieldStringValueHolder object with some utility methods for checking field content
isEmpty() - Checks if the field is empty
isArray() - Check if the field has multiple values
getSingleStringValue() - Return the values as a comma delimited list
getArrayValue() - Returns the value as a String array
getVersionInfo() - Produces a VersionInfoBean object. Null if none is present.If retrieving versions from the source repository, the task will process them in order. Setters are available for all the following as well.
- getTotalVersions() returns and [integer]
- getLabel()
- getFileName()
- getLastModified() returns a [long] in timestamp format
- getFileLength() returns a [long] in bytes
- getPath()
- isLatest() returns a [boolean]
- isMajor() returns a [boolean]
- getObjectId
getFieldsMap() - Returns a map of field names and document field objects. Below is an example script to remove fields with empty values:
var map = rd.getFieldsMap();
for(i in map){
var val = map[i].getFieldValue()[0];
if(typeof val === 'undefined' || val === ''){
log.info('Removing ' + i);
rd.removeField(i);
}
}
Many more methods are available. For a full list see source (RepositoryDocument.java) (Source access required, notify support for more information.)
Jython Script Processing
The purpose of this task is to allow the user to process repository documents using the python scripting language. It does so through the Jython script executor.
The task automatically imports the sys library and sets the document to the variable rd.
The methods available are similar to those out lined in the Javascript Task.
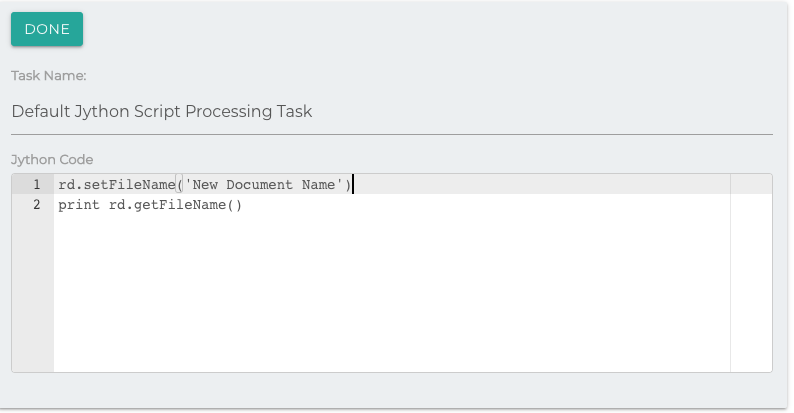
Note that any script placed here will be run on each document individually, which may affect performance.
It is suggested that you test any script you place here before attempting an integration to ensure it is syntactically correct.
Below is an example of removing fields with empty values from the document:
map = rd.getFieldsMap()
for key, value in map.iteritems():
if value.getFieldValue() == '':
print 'Removing ' + key
rd.removeField(key)
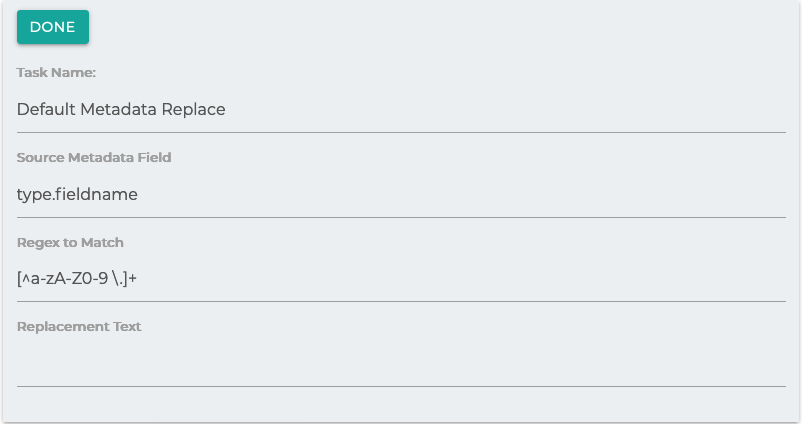
Metadata Replace Job
This task will perform a Regex search on the configured metadata field and replaces it with supplied text.
Source Metadata Field: The field to check.
Regex to Match: A regular expression to use as the first argument of a Java String.replaceAll() method.
Replacement Text: The text to use as the second argument of the replaceAll() method.
Mongo Document Metadata Join
The purposes of this task is to retrieve metadata from an outside mongo database during a migration, adding it to the repository document before mappings are performed.
This task is called a "join" because it checks for a value on both the Repository Document and in the Mongo Document.
The checked field on the Repository Document can be either a standard field mapping, or it can be calculated using the Simflofy Expression Language.
If either checked field is missing, the process will be skipped.
If the values of the checked field matches, the comma delimited list of fields will be added from the Mongo Document, in lowercase.
They can then be added as normal field mappings in a job mapping, as Field mappings take place after Tasks.
Example: ContractStatus in a Mongo Document will be mapped as constractstatus in a field mapping.

Output Metadata As JSON
This task fully converts each document to a json object and exports to it to the configured path on the local filesystem where Simflofy is running.
Output Path: Folder where the json files will be written. Path will be created if it does not exist.
File name pattern = [filename].document.metadata.json
Folder name pattern = [foldername].folder.metadata.json

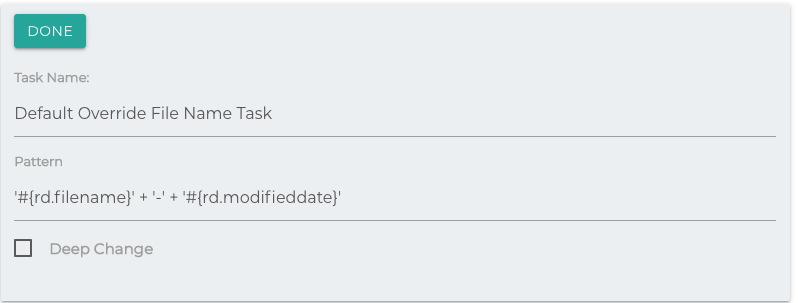
Override File Name
The task uses the Simflofy Expression Language to override the file name of each document.
Functionally identical to the Override Folder Path Task.
Deep Change: If the file has versions, update their names as well.
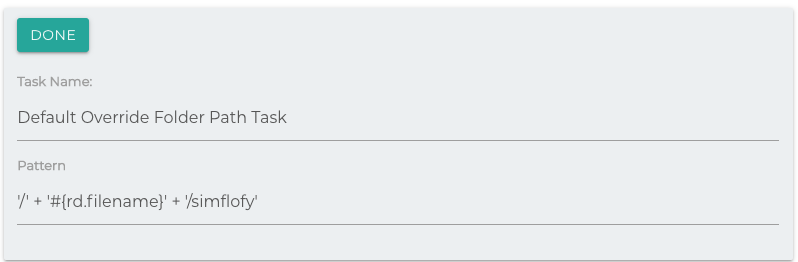
Override Folder Path
Add the Override Folder Path task from the drop-down on your job. Not sure how? Check here.
A sample pattern has been provided for you by default. You can also leverage the Simflofy expression language when modifying your path. More information on the Simflofy Expression Language can be found here. Click the Done button when you have finished modifying your job task.
The example pattern is
'/' + '#{rd.filename}' + '/simflofy'
Using the Simflofy Expression Language you can see that rd. are internal Simflofy Fields.
However, you may want to use metadata from the source system to generate your path.
Use field in place of rd to accomplish this or leave off the prefix entirely.
The best way to put your path together is to know what fields are available and what the field values look like. We suggest running the BFS output with no mappings and Include Un-Mapped Properties set to True. This will generate a xml file such as:
<properties>
<entry key="document.name">Alfresco Ingestion.pptx</entry>
<entry key="type">document</entry>
<entry key="folderpath">testSimflofy_Partners</entry>
<entry key="separator">,</entry>
<entry key="document.Culture">en-US</entry>
<entry key="document.CustomerId">123</entry>
<entry key="document.Category">legal</entry>
<entry key="document.lastindex">23</entry>
</properties>
Now let's say we want the actual folder path to be a combination of folderpath + Culture + Category + Customer ID. To do that we just reference each field like:
'/' + '#{rd.path}' + '/' + '#{document.Culture}'+'/' +
'#{document.Category}'+'/' + '#{document.CustomerId}'
Pause
This task can be useful when outputting to a repository with rate limits, such as Box or SharePoint.
Pause in seconds: How long to pause for each document.
PII Detection
The PII Detection Job Task is uses regex expressions to detect PII in any document or metadata passing through Simflofy. The regex expressions are stored in the form of a .properties file.
PII Flag
This task will always add the boolean field hasPii for the purposes
of mapping and analysis.
Default File Location
The default file is located at simflofy-admin/WEB-INF/classes/simflofy-pii- detection.properties
PII Rules File: The rules files to use.
Field To Mark: The output metadata property to store PII detected. The value of this field will be a map
{
"PhoneNumber": 20,
"Names": 200
}
Fields To Check: Source properties and/or document to check for PII. Use ALL_PROPS to check all properties, BINARY to check the document (extracted via Tika) or individual property names.
Break up pii data into individuals fields: Instead of adding the PII as a map, Simflofy will break it up as individual fields for easier mapping/processing.
Prefix for pii fields: If breaking up PII data, the prefix to use for each field. If left blank 'pii' will be used.
In this case, the above fields will come across as
pii.phonenumber
and
pii.names
Property XML Parser Job
Field to Parse: If the content of the file is the xml to parse, use BINARY. If the xml appears in a field, use the field name.
The xml is expected in the following form:
<rootElement>
<comment>Comment Text Here</comment>
<entry key="fieldName1">fieldValue1</entry>
<entry key="fieldName2">fieldValue2</entry>
</rootElement>
- The root element is named as such for the example. The task searches for "entry" children.
- Comment is an optional field and will be added as comment to the document properties.
Random Date Field Populator
Adds a field with a random ISO Date Time formatted date to a repository document.
Field Name: The name of the field that will receive a random date
Start Date: The minimum time for the random date to fall between. Enter the time as an epoch timestamp.
End Date: The maximum time for the random date to fall between. Enter the time as an epoch timestamp.
Random Field Populator
Field Name: The name of the field to populate.
Field Values: Comma delimited list of values to choose from when populating the field at random.
Remove Mappings
Removes mappings from a repository document if the field has no values.
Source Fields: Comma delimited list of the mappings to remove if it has no values.
Remove Renditions Matching Binary MimeType
This task takes no arguments. It will remove all renditions that have the same MimeType as the Original Document Binary.
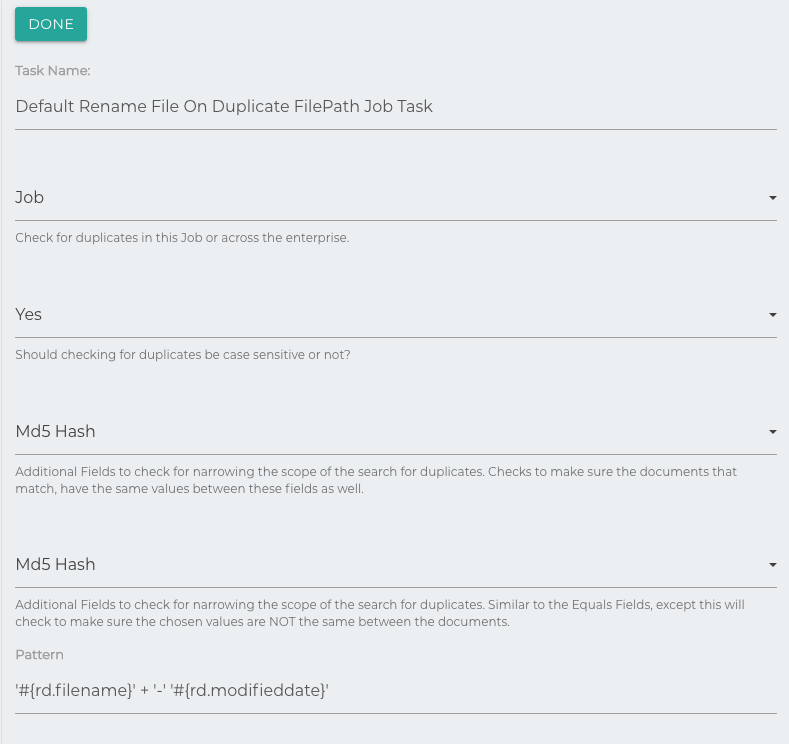
Rename File On Duplicate Filepath
Functions similarly to the Duplication Check Task, except if it finds a duplicate, it will rename the file using the supplied pattern.
S3 Attach Binary
Attaches a binary to the repository document from an S3 bucket.
- S3 Access Key: Your access key for your S3 connection
- Client Secret: Your client secret for your S3 Connection
- Base Folder Path: A base path to be prepended to your key
- S3 Bucket: The bucket to look for the binary in
- Key Field: The field on the repo document that contains the key for S3 bucket lookup.
- S3 Region: The region of your S3 bucket

Separate Binaries
This task is designed to grab a binary from the filesystem given a path set in the form field. The task will look for a file of the same name.
- Expressions should be used to set the path dynamically. ie
/path/to/+#{rd.FileName} - If there is no file at the specified path, the documents will be skipped.
- If there is an error reading the file, an error will be noted in the tasks/job run.

Skip Blank File Name
Skips a file during migration if its file name is blank.
No additional Task Configurations needed.
Skip On Empty Field
This task will skip a document if the supplied fields are all blank.
String to Boolean
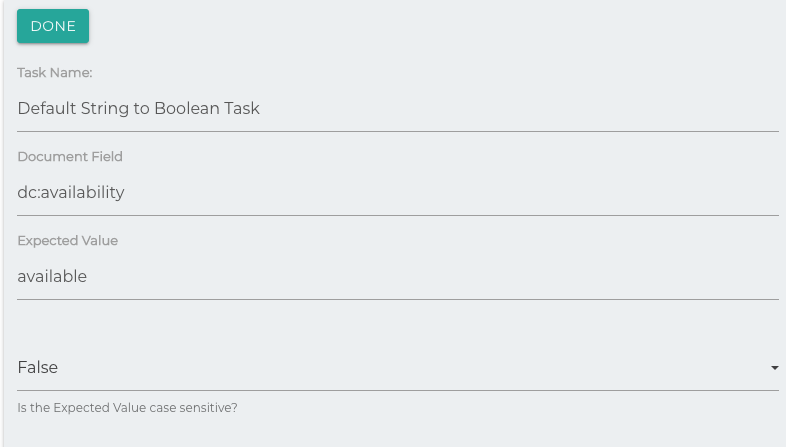
The String to Boolean Task is designed to check the value of a string and return true of it matches the expected value. This is a quick way to convert a string field into a Boolean and is used to manipulate data as it is being processed. You also have the option to specify whether the match should be case-sensitive or not.
Here's an example:
In the above example, we are going to check the field dc:availability. If the string value of that field equals available (Expected Value) the dc:availability field will be updated to a true(boolean). As we elected not to use case sensitivity, the string AvailAble would also return true. Otherwise, a boolean false value will be stored.
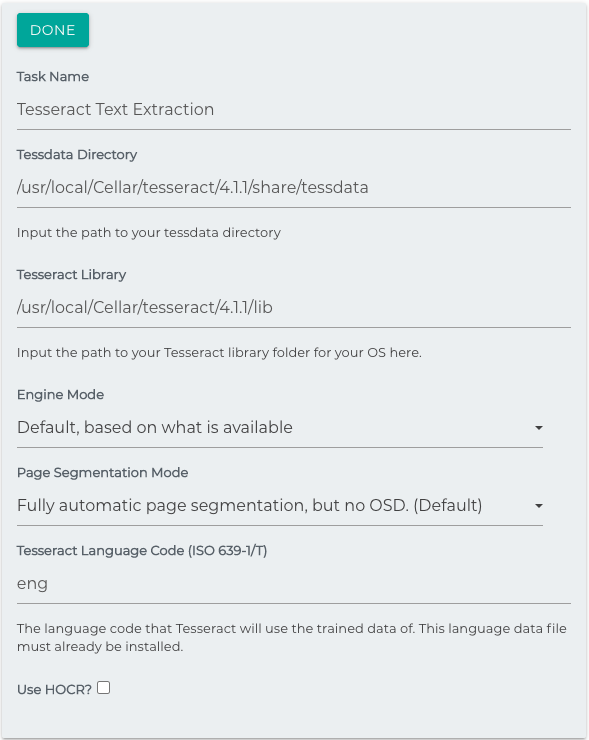
Tesseract Text Extraction
Prerequisite
This task requires Tesseract to be installed on the system that Simflofy is running on.
This task uses Tesseract OCR to scan for text from images and PDF files, saving that text to a field in the repository documented called simflofy_ai_texts. Supported formats are .png, .jpg, .pdf, .tiff, .gif, and .bmp. PDFs are saved on a per-page basis to simflofy_ai_texts.
Configuration
- Tessdata Directory: The path to your tessdata folder. This folder should have the trained data of the language you plan to OCR.
- Tesseract Library: The path to your Tesseract library folder containing the proper library files for your OS.
- Engine Mode: Select which engine Tesseract should use, legacy or LTSM. Ensure that ensure is installed before selecting it, or leave it on the default config for it to detect your engine.
- Page Segmentation Mode: By default Tesseract expects a page of text. You can change the way it segments a page if your images differ from this.
- Tesseract Language Code: The language code for the installed trained data in your Tessdata directory. This is in ISO 639-1/T format and is the letters before the .traineddata extension for the trained data file.
- Use HOCR: Whether to use HOCR. When enabled, text will be output in HTML format rather than as raw text.
Text to PDF
This task takes no arguments, and simply converts text binaries from a Repository Document into a PDF file on output. If the mimetype of the document is not 'text/plain', it will be skipped.
Thumbnail
Generates a thumbnail for a repository document and adds it as a rendition.
Supported File Types
This task currently only supports jpg, png, bmp, wbmp, and gif
- Resize Width: The width of the thumbnail image in pixels
- Action: The integration action to take following thumbnail generation
- Types of Thumb Nails: List of comma delimited file extensions to support
Tika Text Extractor
Apache Tika is an open-source tool used to extract text from documents. Simflofy most commonly uses it to extract text during indexing for federated search.
Tika Content Field: The field where the task will put the extracted content.
Max Content Length (B): Content length, checked before processing. Only extract from documents with length under this value. Set to 0 to process documents of any length.
Content Length to Retrieve (B): The amount of document content to extract. -1 for the entire document.
Fail on Extract: If the extraction fails, fail the document.
Remove Binary: Remove the binary from the documents. Will happen even if document exceeds maximum length.
Stage binary on filesystem: For lower memory systems, stages to the filesystem instead of in memory.
File Extensions to Extract: Comma delimited list of extensions.Extensions are checked at the same time as content length.
Two Way Sync
The Simflofy Two Way Sync Job Task is to filter out any unnecessary documents when doing an incremental sync between two systems. Documents can be filtered by matching MD5 Hash or If the document was just seen in the last run by the other sync Job.
Configuration:
For Two Way Sync you will need to set up two Incremental Migration jobs and chain one Job after the other. You will want to put the Job that should win on a collision as the first Job in the chain.
info
On each Job add the TWO Way Sync Job Task and, if using the MD5 Hash option, you will need to add the MD5 Hash Job Task before the Two Way Sync Job Task.
Check Last Run: If this document was just moved by the other Job in the Sync to this Repository, then let's skip it. If you want to sync it back (maybe after a rule/formula set to false).
Compare MD5 Checksums: Check MD5 Hash of this Document and the Last Document moved by the synced Job. If set to true and MD5 Hashes match, then skip this Document.
Job ID of Other Job: The Job ID of the other chained Job in this Two Way Sync

Watson Image Analysis
Uses IBM Watson Image Analysis to analyze an image, adding its response to a specified field.
- The IAM API: Key for IBM Cloud. See instructions here on how to get it.
- Collection ID: If left blank, Simflofy will create one
- Collection Name: Name of the collection to create. If left blank, will be new-training-collection with the date appended.
- Training Mode: Images will be used in conjunction with the training json to train your analyzer. In this mode, no analysis will be performed.
- The training json: Required for training mode. The format is {"dog":[25,35,105,215]}. Array order is top, left, width, height with object type as the key.
- Field that contains the image urls. If left blank the file content will be used.
Related Articles:
Getting Started With Simflofy
Adding Tasks to Integration Jobs
Federated TSearch Widgets
TSearch Records Management